
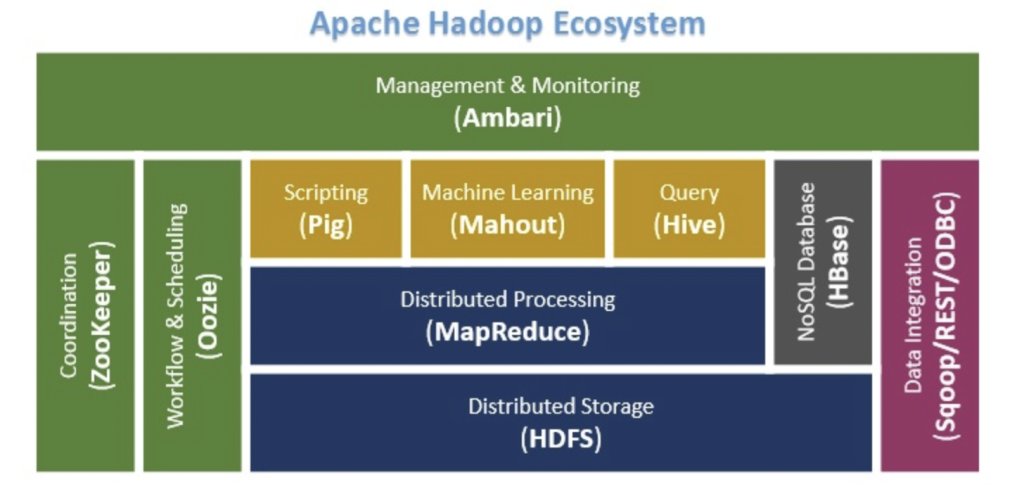
Apache Hadoop is a distributed computing open source framework for storing and processing huge unstructured datasets distributed across different clusters. And here’s the structure of it. The order of presentation is the bottom to the top.
HDFS(Hadoop Distributed File Sysyem)
The storage layer of Hadoop. The default file system that users can drop huge data to HDFS and it’s easy to analysis. HDFS comprises NameNode, DataNode and Secondary NameNode(perhaps optional). NameNode is the master node act as index to track the data. DataNode is slave node that acts as data container. Secondary NameNode is the backup of the NameNode as a cold backup.
MapReduce
The data processing framework of Hadoop. Another indispensable part of Hadoop. It’s a Java-based system developed by Google. It receives tasks from the HDFS storge and breaks a big job into pieces of small jobs. MapReduce is spelled by the words Map and Reduce so it was combined by Map and Reduce.Map job sends a query for processing to various nodes in a Hadoop cluster and the Reduce job collects all the results to output into a single value.
MapReduce is just one framework based on YARN architecture. YARN is for resource management and movement control framework. Samely, you can use other frameworks like tez or spark. Tez is DAG calculating famework and spark is based on RAM while MapReduce is based on disk(offline calculating).
Pig
A platform that able to analyze huge data. You can use Pig Latin which like SQL statement(kind of draft language?). Especially in programming.
Hive
The data warehouse of Hadoop. In order to online analytical processing(OLAP). You are able to use SQL statement and Hive will transfer the SQL statment into jobs of Hadoop.
Oozie
Oozie is a workflow scheduler where the workflows are expressed as Directed Acyclic Graphs. Divide a complete work and distribute tasks.
Zookeeper
Zookeeper is responsible for synchronization service, distributed configuration service and for providing a naming registry for distributed systems.
Hbase
Non-relational distributed database, support random reading and writing.
Sqoop
Used for data transfer in Hadoop(or Hive, Hbase etc.)and traditional databases.
Ambari
Rapid deployment to support cluster supply, management and monitoring.
Comments | NOTHING